- Transcript BART1_0-u57237.006
- Transcript IDBART1_0-u57237.006
- Gene IDBART1_0-u57237

Barley RTD
Exon Structure of BART1_0-u57237.006
| Chromosome | Exon | Start | Stop | Direction |
|---|---|---|---|---|
| chr7H | 1 | 653255206 | 653253979 | - |
| chr7H | 2 | 653255658 | 653255311 | - |
| chr7H | 3 | 653256103 | 653255992 | - |
| chr7H | 4 | 653256324 | 653256237 | - |
| chr7H | 5 | 653257552 | 653257149 | - |
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
Salmon TPM Values: sixteensamplesmorex
These TPM values were generated by using the RNA-seq data from a 16-tissue experiment in Morex (published here) were calculated using Salmon (version Salmon-0.8.2) using BaRTv1.0-QUASI as the reference transcript dataset. Click here for more information about the RNA-seq experiment and materials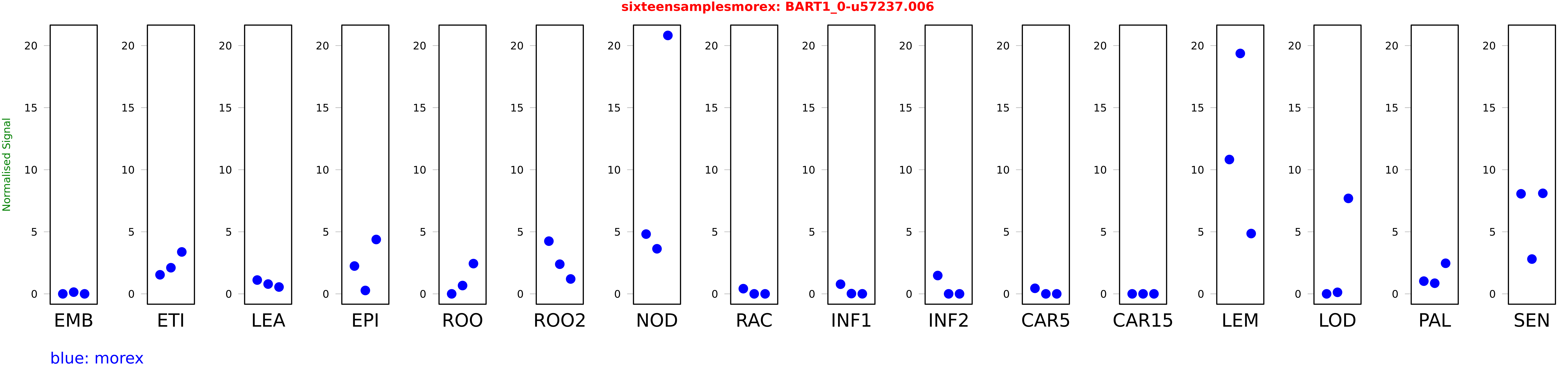
| Sample | Treatment | Rep 1 | Rep 2 | Rep 3 |
|---|---|---|---|---|
| morex | EMB | 0.00000020121 | 0.138396 | 0 |
| morex | ETI | 1.53605 | 2.10489 | 3.3772 |
| morex | LEA | 1.1126 | 0.788275 | 0.550694 |
| morex | EPI | 2.24065 | 0.273366 | 4.38004 |
| morex | ROO | 0.0000509534 | 0.669369 | 2.437 |
| morex | ROO2 | 4.24686 | 2.38893 | 1.19937 |
| morex | NOD | 4.81405 | 3.63161 | 20.8204 |
| morex | RAC | 0.417899 | 0 | 0 |
| morex | INF1 | 0.777312 | 0.020151 | 0.00390877 |
| morex | INF2 | 1.4764 | 0 | 0 |
| morex | CAR5 | 0.447296 | 0 | 0 |
| morex | CAR15 | 0 | 0 | 0 |
| morex | LEM | 10.8229 | 19.3681 | 4.85847 |
| morex | LOD | 0 | 0.124047 | 7.69191 |
| morex | PAL | 1.02468 | 0.85715 | 2.46379 |
| morex | SEN | 8.05961 | 2.80323 | 8.09968 |
Homology to Model Species (BLASTX to E-value < 1e-30)
| Database | Hit | Frame | E-value | Score | % Identity | Description |
|---|---|---|---|---|---|---|
| Rice PP7 | LOC_Os06g51260.1 | +2 | 1e-80 | 243 | 211/403 (52%) | protein|MYB family transcription factor, putative, expressed |
| TAIR PP10 | None | - | - | - | - | - |
| BRACH PP3 | Bradi1g29680.3.p | +2 | 2e-115 | 352 | 238/404 (59%) | pacid=32806209 transcript=Bradi1g29680.3 locus=Bradi1g29680 ID=Bradi1g29680.3.v3.1 annot-version=v3.1 |
Barley PseudoMolecules GBrowse
Click here to see more tracks within GBrowse -->
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
CDS Sequence (2180 bp)
>BART1_0-u57237.006 2180 150831_barley_pseudomolecules CTCCGCCTCCGCTTCCTCCTCCTCCGTCTCCCCCGGCAGCACGTGCGCGCCCCGGCGGCC TCCTCTCTTAGCTGCGCCGCTCGCCGGAGCGTCTCTTCTCGTTTGGCTTCTTTTCTTTGG GTCAGTTTCCTTGGGCCACGGTGTCTCGCCGGCCGGCTCCGGTCGCCGAGAGGGAGGGTG TTTTTTCGGTGCTTCCTGGGCGATCCCGGCGAGAGACGCTTCTGTCCCAGCCTCCGCCGC AGGCCGCCCGCTTCTGTCCCCGCCTTTGCCGCCCGCCGTCTGCTTCTGTCCCCGCCTTCG CCGTCCGCCGTCTGCCGTCTGCTTCGTTCGATCTCGGTGACGGGGACGCCGAGATTCGGA CCTCCGCCGGGGAACGGCTCATGGCTTCCATGGCGCTCGCGGAGGAAACGGATGCACTGG ATTCATCCAGATTGCCGAACGGCAAAGGGTTATCGGTGGATGTTGCAATGCAACCCAATG AGGAGGGGATGGCCTAGGAAGCCATACACGATCACAAAGCAGCGGGAGAAGTGGACGGAC GAAGAGCACGAGAAGTTCCTGGAGGCGCTGAAGCTGTATGGCCGGTCCTGGCGTCAGATA CAAGGTGGTGCGCGAACCCGGAGCTAAAATTGAGATCGAGATCCCTCCCCCTAGGCCAAA GAGGAAGCCGCTGCATCCATATCCTCGCAAGCGTGCGGACTCCTGCAACGGGGCAAACCC AGCAAATGGACCATCCAAGCTTGCTCAAATTTCATCATCTTCTGGTTCTGACCAAGAGAA TGGTTCTCCCGTGTCAGTGTTGTCTGCAATGCAGTCGGATGCTTTTGGATCATCGATGTC AAACCCGTCATCTCGCAGTACTTCCCCAGAGTCGTCAGATGAGGAGAATAATGTTCCTCC AATGGTCAGCAGAGAGGAAGGTCAACAAACAGGGATAAATCAATCCCACAAGGAGGCTGA TCAGGAAAACAAAGATACGGGTACCTCCGAAGAGGATTCTTCTGATGAGGTGCAGGTAAC AAGCGTGAAGCTGTTCGGGAAGACGGTCGTCATCCCAGACCCGAGGAAAAGGTGCTCCCC GGATCCAGGCTCAGGGCATGAAAACGGAGGGCAAACCTCACATTCCTCTAACAAAGGAAC ATCACAAGCCCCACTGGCTGTAGAGATTCCAACACATACAAAGGGAGAACAAATCTCACA ATCCTCTAACAAGGCAACATCACAAGCCCCATTGGCTGTAGAGGTTCCGACGTATACAAA GGGAGAGCAAATCTCACAATTCTCTAACAAGGCAACTTCACAAGCCCCACTGGCTGTAGA AATTCCAGCATTTGCTGCGCCGCCAAGTGGGTGGGTTCTTCCGTACAATTCGTTCCCTCT ACATTTTGGGGAATCGGCGGAAGCCAGAATCACCCCTTTACACATGTGGTGGCCATACTA TGGGTTCCCTATCAGCCACCCTGGAGGGCTGAGTGTAGTGCCGCACAACGAAGCTACTGA TGAGAGCGAAGCTGCAAAGAGCCCTCTGGTTGAATCAAGCTCGAAGAGCCTTCCTGTTGA ATCAAGCTCGGACTCCGATGACAATGCTGAGACAACAGCCAACAAGGAGTGGAAAGTGCT CGAGTCGCTCGGGACGGCACAGGTCCCTCGGTCAGCTTCAAGTTTTCAGCTAAAACCAAG CGAGAACTCGGCTTTTGTGAGAGTGAAGCCGATCATAGGCAGCGGAGAAGAGCCGGCGAG GGGGTTTGTGCCATACAAAAGATGTAGAGTTGAATGACGAAACCGGGGATCTTCTTCCCC GTGTCTAATTTAACTATGAACCCTAGGAGGAGCCTGTTCCACATATTCCTTTGCTCCGGT GTATTCTTAGGTTTTACTCGCACACAGAGATTGGCGGTGGTCTGGCCCAGGAAATGCACG TTGTTTCCTGCTTGGGCCTTGTAATGAGCAGGGCACAGGTGGTTGTTGTAAGTGCTGTAG GATAAAAGCAGGAGGTTTTGTAGGGATGCCAATTCTCTGTCTGTCTCATGTTGTTGATGT AAAAGCAAAGAATTTTTGTGTCACCATTGTTGATTCTTAATGGAAATCGACTTCTCTGAA TGAATGAAGCTGGCATGTTTGGTTGTTGCGGGCTGTTGTGTTGGTAAGAGTCTGAAGATG CTGGTGCCTTTTGTCCCGAG
Protein Sequence (399 aa)
>BART1_0-u57237.006 399 150831_barley_pseudomolecules MAGPGVRYKVVREPGAKIEIEIPPPRPKRKPLHPYPRKRADSCNGANPANGPSKLAQISS SSGSDQENGSPVSVLSAMQSDAFGSSMSNPSSRSTSPESSDEENNVPPMVSREEGQQTGI NQSHKEADQENKDTGTSEEDSSDEVQVTSVKLFGKTVVIPDPRKRCSPDPGSGHENGGQT SHSSNKGTSQAPLAVEIPTHTKGEQISQSSNKATSQAPLAVEVPTYTKGEQISQFSNKAT SQAPLAVEIPAFAAPPSGWVLPYNSFPLHFGESAEARITPLHMWWPYYGFPISHPGGLSV VPHNEATDESEAAKSPLVESSSKSLPVESSSDSDDNAETTANKEWKVLESLGTAQVPRSA SSFQLKPSENSAFVRVKPIIGSGEEPARGFVPYKRCRVE