- Transcript BART1_0-u51812.006
- Transcript IDBART1_0-u51812.006
- Gene IDBART1_0-u51812

Barley RTD
Exon Structure of BART1_0-u51812.006
| Chromosome | Exon | Start | Stop | Direction |
|---|---|---|---|---|
| chr7H | 1 | 140679678 | 140679395 | + |
| chr7H | 2 | 140680474 | 140680127 | + |
| chr7H | 3 | 140680803 | 140680682 | + |
| chr7H | 4 | 140681781 | 140681165 | + |
| chr7H | 5 | 140683083 | 140681885 | + |
| chr7H | 6 | 140684053 | 140683422 | + |
| chr7H | 7 | 140684216 | 140684143 | + |
| chr7H | 8 | 140684701 | 140684566 | + |
| chr7H | 9 | 140685517 | 140684971 | + |
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
Salmon TPM Values: sixteensamplesmorex
These TPM values were generated by using the RNA-seq data from a 16-tissue experiment in Morex (published here) were calculated using Salmon (version Salmon-0.8.2) using BaRTv1.0-QUASI as the reference transcript dataset. Click here for more information about the RNA-seq experiment and materials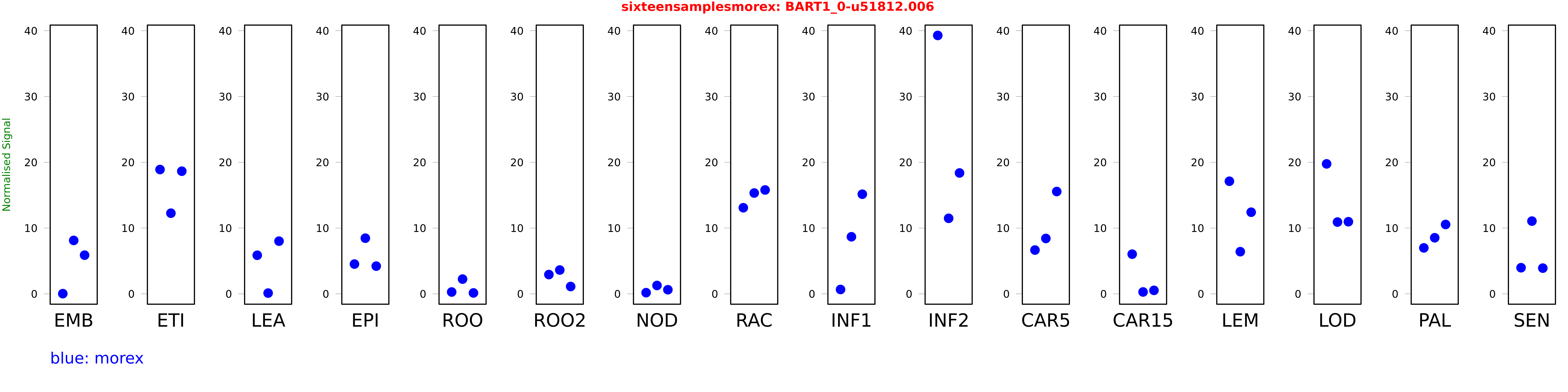
| Sample | Treatment | Rep 1 | Rep 2 | Rep 3 |
|---|---|---|---|---|
| morex | EMB | 0.0303511 | 8.12329 | 5.88199 |
| morex | ETI | 18.8973 | 12.2612 | 18.6452 |
| morex | LEA | 5.8672 | 0.115096 | 8.01263 |
| morex | EPI | 4.52667 | 8.4634 | 4.21438 |
| morex | ROO | 0.280045 | 2.2421 | 0.140448 |
| morex | ROO2 | 2.93075 | 3.62162 | 1.11476 |
| morex | NOD | 0.181532 | 1.27414 | 0.625453 |
| morex | RAC | 13.0898 | 15.3276 | 15.7918 |
| morex | INF1 | 0.665252 | 8.67707 | 15.1462 |
| morex | INF2 | 39.283 | 11.4838 | 18.3755 |
| morex | CAR5 | 6.65906 | 8.42057 | 15.5543 |
| morex | CAR15 | 6.03346 | 0.288408 | 0.531559 |
| morex | LEM | 17.1185 | 6.4106 | 12.41 |
| morex | LOD | 19.7578 | 10.9126 | 10.9663 |
| morex | PAL | 6.98726 | 8.52772 | 10.5463 |
| morex | SEN | 3.97267 | 11.0588 | 3.9105 |
Homology to Model Species (BLASTX to E-value < 1e-30)
| Database | Hit | Frame | E-value | Score | % Identity | Description |
|---|---|---|---|---|---|---|
| Rice PP7 | LOC_Os06g19470.2 | +2 | 0.0 | 627 | 432/680 (64%) | protein|WW domain containing protein, expressed |
| TAIR PP10 | None | - | - | - | - | - |
| BRACH PP3 | Bradi1g43210.1.p | +2 | 0.0 | 746 | 500/682 (73%) | pacid=32799652 transcript=Bradi1g43210.1 locus=Bradi1g43210 ID=Bradi1g43210.1.v3.1 annot-version=v3.1 |
Barley PseudoMolecules GBrowse
Click here to see more tracks within GBrowse -->
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
CDS Sequence (3959 bp)
>BART1_0-u51812.006 3959 150831_barley_pseudomolecules GCTCAACCGAAGCGCCCACCCCGGACACCCGCCTACCGCCAGCTCCCTCCACTTCGCCTC TCCTCCTGATTCGCACCGCTTCCCTTTTTGCCGTAAAACAAAACACCCCGACGTCACCCT CCAAACCCTAACCCTAGAATCTAGAAGACGTCCATCTCCACCCCCGGCGCGCGCCCGACT ACTCGGGGCAGCGGCGATGGGGAGGCGGAAGGAGCGCCGCCTGGCGGCCAAGGCGGCCTC GGGCCGTAGGGTCAAGCTCGACCTCTTCCTCGATCCTTCCCCCGGGGAGGCATCTACTAA AGAGGGAGTAGGGGAGGAAAACCGCGAGCAGCAAACTGGTGTTCCCACTTCACCATCTTC GTCAGGTGGGTTCAATCAATTTCCTTCCAAGGGATATGTAAAGACGGCACATGCCTATGG AATGTAAATTTGGTGGAAATTTGGAATTTTGTTCAAGCATGTGTATGCTCCAAATTTCTG GTTTGAGGCACATGTAGGGTTCCCGGCCTGCAAGGAACACTGAGTAAATTCTTCAGATCA GGCTGCCACTGTCAAAACTGGGTGTGTTCCTACCGGTAATTTCTCTTTTGGCAGCATCTG AGCGTGGGGATTTCAGGATGATTGTTGCCTCGATAAGAAGGAAAATCCTCTAGCGTTGCT TGGGCAATATAGTGATGATGAAGAAGAGGATGAAGTAGCAACAGATCAACCCAATGGTGA AACTAAGGGAAGTTCAACTGATGCAAGTGCCAAGGTTTTTAACGATCATGGTGATGTAAC TGGGGATAAAGGCGATGCAGATAGTGAACTGCCTGCTTCTGTTAGTGTTCAGCAGGAAGC ATCTCAAGCCGATGATGTAAAAACTATCACAGAAAATGTTGCTGAGGAATTTACTGTTGC CCCTGAGCCAACTCTGGAAAATGAGTGTGTGACAGTAATGGAAGCTGTCCCAGATTCATC TGGCATGCAAATCGTGGGTGACATTGGTGGGAATTGGAAGGCTATAATGCATGAACAAAG TAATCAGTGTTACTACTGGAACACAGTTACAGGAGAAACTTCTTGGGAGATTCCTGATGG ATTAGCTTCGGGGGTTGCTGGTGATGGAGTCACTTCTGCATCTGTGCCTACTCATATGGG CTACTCTGTAGAAGCTCAAGCACATGTCCTTCCCCACAGCAATGTTGAAGCATATCCTAG TGATGTATCTGTTGGGAATGGCACAGCAACCTATACTGCTATGGGAACTTATACTCATGA TGCTTATGCTTACACTGGAGCCGTCGCTAGTCATGAGTCAGTGGACATTGACCCCTTGCA GCTTGCAAAATATGGTGAGGATTTACTGCAAAGATTGAAGCTGCTGGAAAGGCCACATGT TGCCATTGACAGTCTTGAGTTGATAAAAAGAGAAATTGAGATACGAGTAGCAGACTGTAA TGCACTCTCCTCGTATGGATCTTCTTTACTTCCATTGTGGTTGCATGCTGAGGTGCACCT TAAGCAACTAGAACTTTCAGTTTCCAAGTTTGAAGCTAGCTACACTACCAGACATGGATA TCTGGAGACGGTGGATGCAGGACACAAAGCACCTAATGAAGCTAAAGTTATGGCACCCTC CGAGGGTGAGCATTTGAAAGTTGATGTTAGCACTCTGGGAATTGGTACTGGCGATGAAAA TATTAAGGTTGAGGAACCATGTACAACATCATCTGCTCAGAACTCACAATGTGTGGCAGC AGCTATTTTAAGAGTTGAATCAGACAGTGATGAAGATATGGACGTGGACATGGAGGTCGA TGAAGAAGGTGTTGAAGAGCACGGCGGATTCACTTCTATGCCAAATAAGGAGCATCCTTC ATCAGAGCAAGTACGATCACCAGCTTTGTCATCATTGGAAGACTCTGCTCCTCCCCAACA GGATAATGACATTCCTCCTCCACCACCACCACCAGAAGAGGAATGGATTCCACCTCCACC ACCGGAGAATGAACCAGCTCCTCCACCTCCTCCTGAGCCTGAAGAGCCTGCTGTGTCATT TGTTCATGCTGATACACTTCCTCAGCCATACGGAGGTCAAGCAAACTTGGGTTATATGCT TCCAGGAATGGAGTACTATCCCGCTTCTGGTACAGATGGCACAAATGCCAGCTACTATAT GCAAGCGAGCGATTCTCATATTCTTCAATCGCAGCAGCATTCTTACTACGCACCGTTGTC TGCAAGTGGCGTATCTATTCCTGTTGAGACCACATCGATCCCCCCAGTACCAGGTTCTTA TTATAGCTATCCTTCTGTCACTATGGCTGCCACTGAAGTAGCGGCTGAATCTTCTGGATA CTATGGTTCATCAACCTCTGCCATTTCTAGCGGTGAATTAGATAACAAAACAAGCTCAGC CTCCCTTGTTTCAAATAGTAATGTGAATCCTGTGGAGTCTGATAAAGTGATATCCAAGGA GCCTACAGTTGTTTCTTTGAGCCAATCAGTAGGGGCAGCCTCAGCTTCAGCACCAACAGT ACATGGTAGTTCTACTCTAGCTTCTACTAGTACCACTAATCAGACTAAAGTTCCTCGTAC TAAGAAGCGACCTGTTGCTGTTGCATCATCACTGAGATCTAATAAGAAGGTCTCAAGTCT GGTGGATAAGGTATCTCCCTGACCTCCCAAAGCTGCTGTTAAAATAGTGACCATCTCTGC TCTCTCCTACCCTACCATCAACTGCTCCCAAGTGTGGTGCTTGACATCAATGAAGAAATT TAACTCACTGCATGATATGCATTATTGCTAATGGTGTATACTTAGTCGTTGAGACATACT CTTGGTTATGTTATTAGCAAGAGAGCACACTGTCCTCGGCCAGTTTATTTCGTGGTGCAC AACATTGGTCCTCCAGAAAAAAAACTCATGCAAGTGGGAGTATGGCCGTGTTTCCTGACT ATTTCGTCTCATGTTTATCATTTCTTATTTTAAAGGCAGAGCAATCTGTTTACATGGTAA TTGGTAAGGCTTAAGACAAGGTGAGTGTTGATGTATAATGATTGTTTCCTTATTAATCTA CCTTTACTAAAGCGACCTTTTATTTTATTTTATTTCACTATTACAGTGGAAAGCTGCAAA AGAGGAGCTTTGTGATGAAGAGGAAGAGGAGCCTGAAGATGCTTTGGAGTACCTAGAAAG GAAACGTCGGAAGGAAATAGATGGGTGGCGTAAGCAACAAATAGCTAGTGGAGAAGCTAA GGAAAATGCTAATTTTGTTCCCCTTGGCGGTAACTGGCGTGACCGTGTAAAACGCAAAAG AGCTGAAGCAAAGAAGGAAGCAAAGACTGAATCTGTTTGTGCAGCTGCCGAACAACACAA AGGAGAGCCTGATCTCTCAGAGCTTTCCAAGGGTCTCCCTTCTGGGTGGCAGGCATACAT AGACGAGTCTACGAAGCAAGTGTACTATGGGAACAACCTCACTTCCGAGACTACTTGGGA TCGGCCTAGCAAATAAAGATTGAACTAGTTGAAGATGGTCCAGTTTTGCTCTGTAGATAT CCTCATACATCTATACGTTGCCTGTCTGGTTATGAGGCTGTATTGTTTCTTTTATTTTCC ACTGGGAGATCGTAGCAGGAAGGATACTTCATTTTGGTATATAGAGGCATCCCTTGTAAG AGTGGCAACTTGAGATCGAATTACTGAAGCAAAAAATACTAGTTAGTTGCTGACCAAGGA AAAATGTGCCTTGTTAAGTGGTGGGAGTCTTTACCTCGATCTGATACCATTTGCTTTCAA AACAATGTCAATTATATTCGATTTTAGGTTGTGCTAAATTCTAGACTTCTCCAATTATTT AACATTAGAAAGAAAGATGATTTTTAAGTTTTTTTTCACACTTATTTTTTTTTTAAACTT CAAAATGCCCTCGGACATCATTGGCTGGATTTTGTTTACATCATGCGATCTAAGTTTCG
Protein Sequence (574 aa)
>BART1_0-u51812.006 574 150831_barley_pseudomolecules MEAVPDSSGMQIVGDIGGNWKAIMHEQSNQCYYWNTVTGETSWEIPDGLASGVAGDGVTS ASVPTHMGYSVEAQAHVLPHSNVEAYPSDVSVGNGTATYTAMGTYTHDAYAYTGAVASHE SVDIDPLQLAKYGEDLLQRLKLLERPHVAIDSLELIKREIEIRVADCNALSSYGSSLLPL WLHAEVHLKQLELSVSKFEASYTTRHGYLETVDAGHKAPNEAKVMAPSEGEHLKVDVSTL GIGTGDENIKVEEPCTTSSAQNSQCVAAAILRVESDSDEDMDVDMEVDEEGVEEHGGFTS MPNKEHPSSEQVRSPALSSLEDSAPPQQDNDIPPPPPPPEEEWIPPPPPENEPAPPPPPE PEEPAVSFVHADTLPQPYGGQANLGYMLPGMEYYPASGTDGTNASYYMQASDSHILQSQQ HSYYAPLSASGVSIPVETTSIPPVPGSYYSYPSVTMAATEVAAESSGYYGSSTSAISSGE LDNKTSSASLVSNSNVNPVESDKVISKEPTVVSLSQSVGAASASAPTVHGSSTLASTSTT NQTKVPRTKKRPVAVASSLRSNKKVSSLVDKVSP