- Transcript BART1_0-u30899.018
- Transcript IDBART1_0-u30899.018
- Gene IDBART1_0-u30899

Barley RTD
Exon Structure of BART1_0-u30899.018
| Chromosome | Exon | Start | Stop | Direction |
|---|---|---|---|---|
| chr4H | 1 | 593062202 | 593062192 | + |
| chr4H | 2 | 593063161 | 593063098 | + |
| chr4H | 3 | 593068884 | 593066220 | + |
| chr4H | 4 | 593070220 | 593069549 | + |
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
Salmon TPM Values: sixteensamplesmorex
These TPM values were generated by using the RNA-seq data from a 16-tissue experiment in Morex (published here) were calculated using Salmon (version Salmon-0.8.2) using BaRTv1.0-QUASI as the reference transcript dataset. Click here for more information about the RNA-seq experiment and materials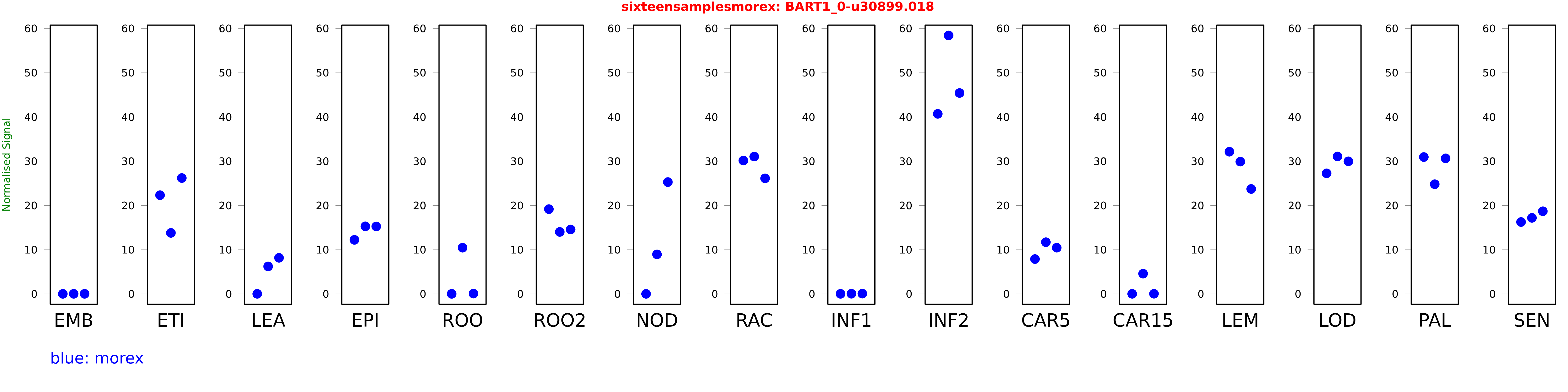
| Sample | Treatment | Rep 1 | Rep 2 | Rep 3 |
|---|---|---|---|---|
| morex | EMB | 0.000365208 | 0.00702513 | 0.00491751 |
| morex | ETI | 22.3118 | 13.7827 | 26.19 |
| morex | LEA | 0.0059943 | 6.20103 | 8.14701 |
| morex | EPI | 12.209 | 15.2712 | 15.2431 |
| morex | ROO | 0.00000373661 | 10.4283 | 0.0501748 |
| morex | ROO2 | 19.1567 | 14.0016 | 14.5592 |
| morex | NOD | 0.00000411916 | 8.92937 | 25.2758 |
| morex | RAC | 30.1458 | 31.0392 | 26.1196 |
| morex | INF1 | 0.00339847 | 0.0227549 | 0.0451843 |
| morex | INF2 | 40.7003 | 58.4349 | 45.4159 |
| morex | CAR5 | 7.8674 | 11.6803 | 10.4317 |
| morex | CAR15 | 0.00845957 | 4.56738 | 0.0250289 |
| morex | LEM | 32.134 | 29.893 | 23.7169 |
| morex | LOD | 27.2578 | 31.0755 | 29.9759 |
| morex | PAL | 30.9344 | 24.7914 | 30.6431 |
| morex | SEN | 16.244 | 17.182 | 18.6738 |
Homology to Model Species (BLASTX to E-value < 1e-30)
| Database | Hit | Frame | E-value | Score | % Identity | Description |
|---|---|---|---|---|---|---|
| Rice PP7 | LOC_Os11g38900.1 | +2 | 0.0 | 1229 | 648/853 (76%) | protein|histone-lysine N-methyltransferase, H3 lysine-9 specific SUVH1, putative, expressed |
| TAIR PP10 | AT1G73100 @ ARAPORT AT1G73100.1 @ TAIR |
+2 | 0.0 | 556 | 272/511 (53%) | Symbols: SUVH3, SDG19 | SU(VAR)3-9 homolog 3 | chr1:27491970-27493979 FORWARD LENGTH=669 |
| BRACH PP3 | Bradi1g53840.1.p | +2 | 0.0 | 1292 | 687/855 (80%) | pacid=32801893 transcript=Bradi1g53840.1 locus=Bradi1g53840 ID=Bradi1g53840.1.v3.1 annot-version=v3.1 |
Barley PseudoMolecules GBrowse
Click here to see more tracks within GBrowse -->
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
CDS Sequence (3412 bp)
>BART1_0-u30899.018 3412 150831_barley_pseudomolecules TCCCAACCAAGGGATTTTTCTCTCCTCGTGTGTTGTGCAGTGCTTTGTGCCAACACGTGG GACTGCAAGTGTTGGCTTTCTCCGAAGTATGGCTTGTGGACAAGTGTAGACCTGTAGACA AAGAGACAAAGAAATTGCTGACATAAGTCCTTATTTGAGAAAGATCAGTTGTCAGCTTAC AATGGCTGGAAATCAGCAGCCGGCTTCAGTTGTGTTGGATTATGCAGCAGTCCTCGACGC CAAACCCTTGCGCACACTGACCCCCATGTTCCCTGCACCGCTAGGGATGCACACTTTCAC CCCTAAAAGCTCATCTTCAGTTGTCTGTGTCACCCCGTTTGGACCATATGCTGGAGGTAC CGAACTGGGAATGCCTGGTGGTGTTCCGCCAATGTTAACATCACCGTCCGCTTCTGCAGA TCCCAAGCAGGTGCAGCCATATACGGTTCATATGAATGGAACTTCTAATGCTAATGGTAC TACAAGCAACACAATGGTTACCCCTGTGTTGCAAACTCCTCCAGCAGTCACTACACAGGA GTCTGGTAAGAAGAAGAGGGGGATGGTTACCCCTGTGTTGCAAACTCCTCCAACAGTTAC TACACAGGAGTCTGGTAAGAAGAAGAGGGGGAGGCCCAGGCGTGTGCAAGATACAACTAC TGTTCCCCCGGTTCCTCCAGTTCAACCGGTTCCTACAGTTCATTCAGTTCCTTCAGCTCC TCCAGAAGTTAATAATATTGTTCTCCAGACACCTACTTCAGCCGTCTCACAGGAATCTGG TAAGAGGAAGAGGGGACGACCCAAGCGTGTGCCAGATGTTTCTGTCTTATCAACTCCAGT GCCTGTAGCAGATGGTACGCCTATTTTACAGACACCTCCTGCATCTAGTGTACATGAATC TGTTACAAAGAAAAGGGGGCGGCGATCCAAGCTTGTGCAGGATATTTCAGATACTTCAAC TCCCCCAGTTCATTCAAAAGAGAGTGAGCCCTTTATGCAGACTCCTGCAGTCACCGTATT GGAGGATGGTAAGAGGAAGAGAGGGCGGCCGAAGCGTGTGCCTGATAGTTCAGTGACTCC TTCAAGTCATTCTGTCCTTACAGTAGATGTTGACAGTGGTGACACATCAAAACGTGGCCG GCCTAGAAAAATTGACACAAGCCTATTGCACCTGCCATCTTTGTTTTCAGACGATCCCAG GGAATCCACAGATAATATACTTATGATGTTTGATGCACTGCGACGGCGGCTCATGCAGCT GGATGAGGTGAAGCAAGTAGCAAAACAGCAGCAAAACTTGAAGGCTGGGAGTATCATGAT GAGCGCTGAACTTCGCCTCAGTAAGAACAAGAGGATTGGAGAGGTTCCAGGTGTTGAGGT TGGTGACATGTTCTACTTCAGAATTGAGATGTGCCTGGTAGGGTTAAATAGTCAGAGCAT GGCAGGGATAGATTATATGTCTGCTAAGTTTGGTAACGAGGAGGACCCCGTGGCCATTAG TATTGTGTCAGCTGGTGTGTATGAGGATGCTGAAGATAATGATCCAGATGTTCTGGTTTA CAGTGGACATGGCATGTCTGGTAAGGATGACCAAAAGCTTGAGAGAGGTAATCTTGCACT GGAGAGAAGTTTGCATAGGGGTAATCCCATTAGAGTCGTTCGCACTGTGAAAGACTTGAC TTGTTCAACTGGTAAGATATACATATATGATGGCCTTTACAGGATCAGAGAAGCCTGGGT AGAGAAAGGTAAATCTGGTTTCAATATGTTTAAACACAAGTTGCTCAGAGAACCTGGACA ACCTGATGGCATTGCAGTGTGGAAGAAGACTGAAAAATGGAGGGAAAATCCATCCTCTAG AGATCGTGTTATAGTGCACGACATATCATACGGTGTGGAAAGTAAGCCTATCTGCCTTGT AAATGAGGTTGACGATGAGAAAGGTCCTAGCCACTTCACGTATACAACTAAACTTAACTA CATGAATTCCCCAAGCTCAATGAGAAAGATGCAAGGCTGCAAATGCACAAGCGTATGCCT ACCCGGTGATAACAACTGTTCTTGTACGCATCGAAATGCTGGTGACCTTCCTTACAGTGC TTCGGGCATACTTGTTAGTCGGATGCCTATGTTATATGAGTGCAATGATTCATGCACTTG TTTACATAATTGCCGGAACCGGGTTGTACAAAAAGGTATCAAGATCCACTTTGAGGTGTT TAAAACGGGAGATCGAGGCTGGGGCCTGCGTAGTTGGGATCCAATCCGAGCAGGCACATT CATCTGTGAATATGCAGGTGTAATTGTTGACAAGAATGCTCTTGATGCAGAAGATGATTA TATCTTTGAGACCCCTCCTTCGGAGCAGAACTTAAGATGGAACTATGCACCAGAATTACT GGGTGAACCTAGTCTTTCTGACTTAAATGAATCATCTAAGCAGTTGCCAATAATTATTAG TGCAAAATATACTGGTAACATAGCTCGCTTCATGAACCACAGCTGCTCACCTAATGTTTT TTGGCAACCAGTTCTGTATGACCATGGTGATGAGGGATATCCACACATCGCATTCTTTGC AATTAAGCATATTCCTCCAATGACAGAGCTTACATATGATTATGGTCAGAGCGGTAATTC AGGGTGTCGGAGGTCTAAAAGTTGCTTATGTTGGTCTCGCAAGTGCAGGGGTTCCTTTGG CTAAATAATCAACCCTTAAGGGATACTTTCCTAGTTGAAGAAGCAGCTTATGGTGGCGGC GGCATTATGGGTGTGGTGTTCCAGCCACAGTTGAAATAACTTTGCTGCCTCTTTCTATCC GGGGTTGGAATGCGGGGTAGAGTACAAACGACTAGATGTTGTAATAAAGGGCAAGCTATG CTTCTGTGGTGTTGTTAGTTGTAGTTGTCTGCTCCGGTTTAAGACCACCCAGTGGAATTC CTTCTATGTATTGTCATTGCGAAGATGTTTCAAGCCTGCAGTGAATCTATCGTTTTCGAT TTGTAATCCTAGCGGATTAATGTGTCCTGTGAATCTGTGATTGCCGTGGAGAGCGAATGA AGGCAACAATAATAATCCAGCTGGGCATTGTTCGTGCAGGGGTAAAGATAGGGGCAGAGT CAGTGCTGTGCGCTTGATTTATGATTCGGTGAATGACTTTGATGGTTGATTGCTTAGATT CGCTGCTTTTGTTCTGTAGCGATCTTTATTTTCTTCTTATTCTAACCCTATTCTCTCTGA AATTTGTTTTTCTGTTCTTGTTCAGATTTGGTGTGAAGGATGGTGCTCTGTTCCTATGAG CAGTAGGCTCGCTGGGATTTTGGGCTTTGCCGTGTATTTTGGTCCCTGCTTGGCATACCG TTTTCTGCACATTACAGGTGTAAAATAAATACAGACCTCCATCCACTGGTTT
Protein Sequence (840 aa)
>BART1_0-u30899.018 840 150831_barley_pseudomolecules MAGNQQPASVVLDYAAVLDAKPLRTLTPMFPAPLGMHTFTPKSSSSVVCVTPFGPYAGGT ELGMPGGVPPMLTSPSASADPKQVQPYTVHMNGTSNANGTTSNTMVTPVLQTPPAVTTQE SGKKKRGMVTPVLQTPPTVTTQESGKKKRGRPRRVQDTTTVPPVPPVQPVPTVHSVPSAP PEVNNIVLQTPTSAVSQESGKRKRGRPKRVPDVSVLSTPVPVADGTPILQTPPASSVHES VTKKRGRRSKLVQDISDTSTPPVHSKESEPFMQTPAVTVLEDGKRKRGRPKRVPDSSVTP SSHSVLTVDVDSGDTSKRGRPRKIDTSLLHLPSLFSDDPRESTDNILMMFDALRRRLMQL DEVKQVAKQQQNLKAGSIMMSAELRLSKNKRIGEVPGVEVGDMFYFRIEMCLVGLNSQSM AGIDYMSAKFGNEEDPVAISIVSAGVYEDAEDNDPDVLVYSGHGMSGKDDQKLERGNLAL ERSLHRGNPIRVVRTVKDLTCSTGKIYIYDGLYRIREAWVEKGKSGFNMFKHKLLREPGQ PDGIAVWKKTEKWRENPSSRDRVIVHDISYGVESKPICLVNEVDDEKGPSHFTYTTKLNY MNSPSSMRKMQGCKCTSVCLPGDNNCSCTHRNAGDLPYSASGILVSRMPMLYECNDSCTC LHNCRNRVVQKGIKIHFEVFKTGDRGWGLRSWDPIRAGTFICEYAGVIVDKNALDAEDDY IFETPPSEQNLRWNYAPELLGEPSLSDLNESSKQLPIIISAKYTGNIARFMNHSCSPNVF WQPVLYDHGDEGYPHIAFFAIKHIPPMTELTYDYGQSGNSGCRRSKSCLCWSRKCRGSFG