- Transcript BART1_0-u54453.024
- Transcript IDBART1_0-u54453.024
- Gene IDBART1_0-u54453

Barley RTD
Exon Structure of BART1_0-u54453.024
| Chromosome | Exon | Start | Stop | Direction |
|---|---|---|---|---|
| chr7H | 1 | 514441144 | 514440926 | - |
| chr7H | 2 | 514442292 | 514442135 | - |
| chr7H | 3 | 514442474 | 514442367 | - |
| chr7H | 4 | 514442603 | 514442556 | - |
| chr7H | 5 | 514443079 | 514442719 | - |
| chr7H | 6 | 514443422 | 514443298 | - |
| chr7H | 7 | 514444718 | 514443512 | - |
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
Salmon TPM Values: sixteensamplesmorex
These TPM values were generated by using the RNA-seq data from a 16-tissue experiment in Morex (published here) were calculated using Salmon (version Salmon-0.8.2) using BaRTv1.0-QUASI as the reference transcript dataset. Click here for more information about the RNA-seq experiment and materials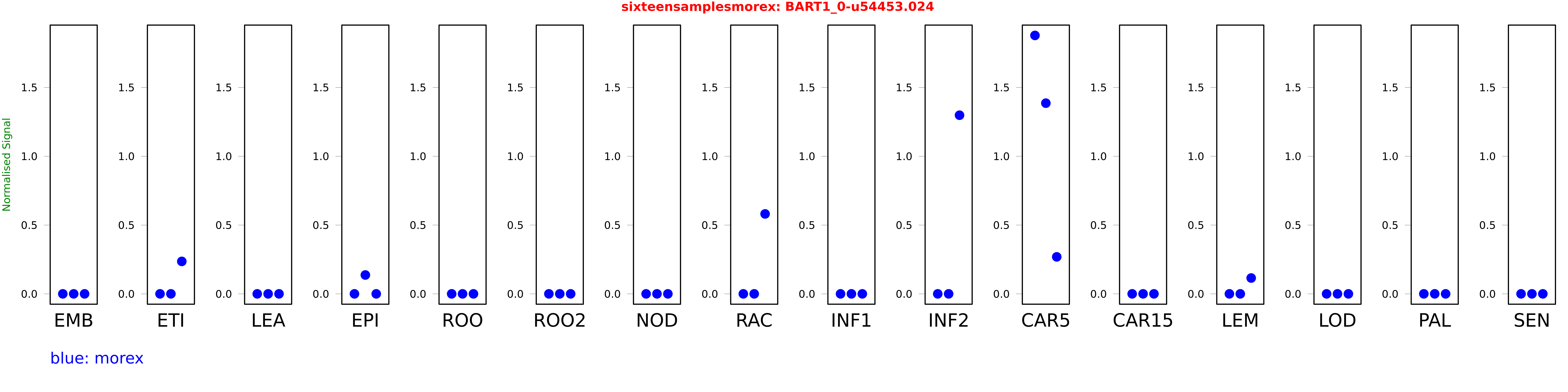
| Sample | Treatment | Rep 1 | Rep 2 | Rep 3 |
|---|---|---|---|---|
| morex | EMB | 0 | 0 | 0 |
| morex | ETI | 0 | 0 | 0.235908 |
| morex | LEA | 0 | 0 | 0 |
| morex | EPI | 0 | 0.137011 | 0 |
| morex | ROO | 0 | 0 | 0 |
| morex | ROO2 | 0 | 0 | 0 |
| morex | NOD | 0 | 0 | 0 |
| morex | RAC | 0 | 0 | 0.580967 |
| morex | INF1 | 0 | 0 | 0 |
| morex | INF2 | 0 | 0 | 1.29845 |
| morex | CAR5 | 1.87843 | 1.38605 | 0.26889 |
| morex | CAR15 | 0 | 0 | 0 |
| morex | LEM | 0 | 0 | 0.115081 |
| morex | LOD | 0 | 0 | 0 |
| morex | PAL | 0 | 0 | 0 |
| morex | SEN | 0 | 0 | 0 |
Homology to Model Species (BLASTX to E-value < 1e-30)
| Database | Hit | Frame | E-value | Score | % Identity | Description |
|---|---|---|---|---|---|---|
| Rice PP7 | LOC_Os08g09250.2 | +2 | 8e-148 | 237 | 113/127 (89%) | protein|glyoxalase family protein, putative, expressed |
| TAIR PP10 | AT1G11840 @ ARAPORT AT1G11840.6 @ TAIR |
+2 | 3e-115 | 193 | 93/132 (70%) | Symbols: GLX1 | glyoxalase I homolog | chr1:3995928-3997518 FORWARD LENGTH=322 |
| BRACH PP3 | Bradi2g31810.1.p | +2 | 1e-112 | 197 | 97/127 (76%) | pacid=32770913 transcript=Bradi2g31810.1 locus=Bradi2g31810 ID=Bradi2g31810.1.v3.1 annot-version=v3.1 |
Barley PseudoMolecules GBrowse
Click here to see more tracks within GBrowse -->
grey: non-coding, green: Barley Morex IBSC 2017 Transcript CDS, red: Barley RTD exons
CDS Sequence (2226 bp)
>BART1_0-u54453.024 2226 150831_barley_pseudomolecules CCGACACGCGCCCACAGCCCATCTGGCCAGCTTTAGTGGGAGGGATGCGCTTTTACAGCC TGTGAGGAGGTACCACGTCGCCATCAACGCAATCATAAGTATCGGTGCCGGACTCTCTTC TCCTTGGAAGCCTCTAGACTGAGCTCCTCATCAGCGTGGGACGGATCTCTGCCGGATCGT ATTTCCGGGGTGAGCATCCCCAAATCCATCTCCTTCGTCCTCTCTTCCGCTTGCTTCCTT TACGCGCCGGTGCGTAGTTTTCCGATTCGCCGTTCCTTTAATGTCTGCTTGTAGATTTCT TACAGGTTTCTGATAGATGGCCTCCTTCCCTTTCTTATTTGGATTCGTATCTGTATGTAG TTTGATTTGTTTCAAGCACTGCGTCTGGGGAGGATTTTTGGAAAACAGAGTGAATCATGG GAAAACCCCCGATCCGGATTTTTTAGAACCACCCCCAATCCAACTATGCGTGCAGTTTGC TGGTTTTTATTTTTATTTTTACTTTGATTTAGCAGAACATCTTCCTGGCGTGGTAGCGGC TGGGCTGTGGGGGAGGTGCTCATGGATGGATTGGGATCCTTTCGCCTCAGCGCAGGGATT TGGGGGCGCTACTTATTTATCCAGTCCTGCCGCTAGTTGCTGCTAATTTATCCAGTGATG CTGCTGTTACTCACTACTGTATTCTTTTGCTTTTAGGGAGGTGCAGTATTTAGTTAGGAT AATTTTGATAGAGGAGTGCTGTTGCTACTGTATTCTTTTGCTTTTACTTCCTTTGTTCCT AAATATAAGACCTTTTAGAGATTTCACTATAGACTTAGTTTGGAGTGTAGATTCTTTTAT TTTGCTCCGTATGGATTCTATAGTAGAATCTCTAAAAGGTTTTATATTTAGGAACGAAGG GAGTATACGATATATAGGAGAGAGTATAGACAATCTGCTGGAAAACTAGAAATTTTGAGA GGGAATCGTTTTGGACCATTGTCTATATATATATATATACACACACACACAAGCTGCTAC AGATGCTCTTACCTCTTTCCTTGCTATAATAATTGAGTGCATAACAACTCTTACAGGTGA CAACAGGGATGGCTACCGGTAGCGAAGCTGGAAAGTCCGCCGAGGCCGTGCTGGAATGGC CTAAGCAGGACAAAAAGAGGATGCTGCATGCTGTTTACCGTGTGGGAGATCTTGACAAAA CCATTAAGTGTTACACAGAATGCTTTGGGATGAAGCTGCTGAGGAAAAGAGATGTCCCAG AAGAGAAGTACACCAATGCGTTTCTTGGGTTTGGACCTGAGGATACTAATTTTGCACTTG AGCTGACTTACAATTATGGTGTTGACAAGTACGACATTGGAGCGGGCTTTGGACATTTTG CCATCGCAAATGAGGATGTATGTATTGTTTACCTGCAACATCTTACCCTTTATGTTACAG ACCCTTGGGCTTGTTTGATGTCATGGATGCAATGCAGGTGTACAAGCTGTCTGAGACAAT TAAATCATCTGATTGTTGTAAGATCACTCGTGAACCTGGTCCTGTCAAGGGAGGGTCCAC TGTGATTGCCTTTGCACAAGACCCAGATGGTTACTTGTTTGAGCTTATCCAGAGGGGTCC GACGCCTGAGCCTCTCTGTCAAGTTATGCTTCGTGTTGGTGACCTTGATCGGGCTATCAT GTTCTACGAGAAGGCCCTTGGGATGAAGCTTCTGAGGAAGAAGGATGTGCCTCAGTATAA GTACACCATTGCCATGATGGGCTATGCTGAGGAGGACAAGACCACTGTTCTGGAGTTGAC ATACAACTATGGTGTCACGGAATATAACAAGGGCAATGCATATGCTCAGTGCAGGTTGCT ATTGGCACTGACGATGTGTACAAGAGCGCCGAAGCAGTTGAGCTGGTTACCAAAGAACTA GGTGGAAAGATTCTAAGGCAGCCAGGGCCACTACCGGGGCTGAACACCAAAATCACCTCT TTCCTTGACCCAGATGGCTGGAAAGTGGTTCTGGTGGACTACGCAGACTTCCTCAAGGAG CTGCACTGAAGATGAGCAGGCTCAGATGTTAGTGTCGTGAGGAGGAACCGTATGTAGCAA TGGTCTGTGTGATGTAATAAAACAAACCTCATGTAGCAAATGGTCTGTGTGCGATGTAAT AAAAAGGCAGCCTCTTCCGCTCGACGAATAAAAATAAAAGCAACTACCGCATGCCCATGC CGTCAT
Protein Sequence (173 aa)
>BART1_0-u54453.024 173 150831_barley_pseudomolecules MYCLPATSYPLCYRPLGLFDVMDAMQVYKLSETIKSSDCCKITREPGPVKGGSTVIAFAQ DPDGYLFELIQRGPTPEPLCQVMLRVGDLDRAIMFYEKALGMKLLRKKDVPQYKYTIAMM GYAEEDKTTVLELTYNYGVTEYNKGNAYAQCRLLLALTMCTRAPKQLSWLPKN