| Morex x Barke POPSEQ 2013 | Oregon Wolfe POPSEQ 2013 | Morex Genome Release 2012 |
|---|
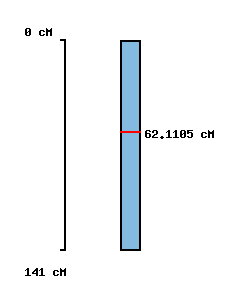 |
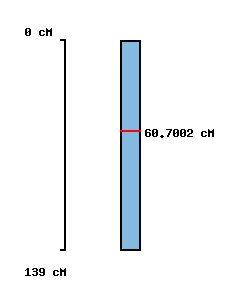 |
No map location |
Predicted Genes from contig_38401
| Gene ID | # CDS Predicted | Max CDS Length | Probes in Cluster | FPKM by Treatment | FPKM by Replicate | Top Rice Hit |
|---|
| MLOC_53487 |
2 |
536 bp |
AK360070 |
Not available |
Available |
None |
CDS Structure of MLOC_53487

Contig Sequence (1742 bp)
>contig_38401 1742 assembly3_WGSMorex_rbca.fasta
GGGGGTTACCTTGGAGGGGTCGACCTTGGGGTGGCACTTGATGACGTCGAGGACGCGGTC
GACGACCTCGTCGCGGGTAAGGTGGGCGTCGTGGGAGGACATTGGCCGCGCGAGCCACCG
CGCGAGGGCGAGGGGCTGGCCGGCCGCGGTGGCGCCGACGAGAGGGGCCGCCATGGCGGG
GGAGAGTCGGATGTGGCGGAGGATCGCCGGACGTAGTGCTGCCGCCGCCATCTTCCTGTC
CGCCTTTCTCTTCGCTCGGGATTTCGACCTCACCGTTCGTCGGCCTCTCTGCTATGCGAG
CGTCTACAAGGATCCCCTCACTGATCTTTGACCTCACCTCACCTAAATCTCCACCTACAC
TTGTATCAGTGTTCCAAATTCTGGGCCCACCTGTCATACGAGACATACACATACACGAAA
CAATTCCCCTGAAGATGGCACCCACCGGTTTTGGAAAATGTTTAATTTCATTCGGATGGA
TTTTCTCTCCCTTAAACCGCTCTCTTCGCTTACCAAGTGCCCCTGTGAGGGTCCGCCCAC
TGCTTGGGTCCCCTTCACCTTATCTTCTCGACGGTGTCAATCCATCATCAGTTTCTCTTT
CTTTTCCTCTTTCTCGTTCATGACGCAATAAAGGAGAGGCAACACCACAACCTGCAGTGG
AGGAGGGGACAACCGTCGGCGCCGCCTTGATTCATCCCACGTCGAGGTTGCGAGGGGACA
ACAGTCGCCGCCGCCTTGATTCATCCCATGTCGGGGGTTGCGATGGAGCGCCGCTGCAAC
TGTATTGGAGCGTGGCCAGGGCTACATAGCTACATATTCCTACGATGCATCACAACTTCA
GCCATGGTCATTGTGTGCTGCATCCTAGCACCCATCGCCACCGGCGCCGCATCACAACAC
GCACCATCATCGTCAGTGTTGCATCTCAACATCCCTCAAGTTGCGTCGCAGCTCCCGCCA
TGGCCGCCGCGTGCTGCGTCCCAGCACTCATCACTGTGGGTGCTGCATCGCAGCAACCAC
CGCACCGAGTTTAATCTTCTACCGCCGTCGCCGCGCGCTGCATCGAAACATCCCGCCCTG
CATCGCAACTCCTGGCATGGTCGTCGCATGTTGCGTTGGAAAACCGTCGTCGCGAGTGCT
GCATCACAGCAACCACTTACGTAGTCACACTGTGCTGCATCGCAACATCAGCCATGCTCG
TCGTGCGCTGCTCATCGGCATTGCTACTGTCCGTTTCGCAGCGGGGAACTGTTGCGTGTG
CTCGGGGAAGAAGAAAGTAATGGACCGATGCTCGAGGGAGGAAGGAAGCGATGAAGCATC
GTTAACCTATCTAACGGTTTAGCCACGATGGATCGAACGACTATGGACCCGACTGATTTC
CCTAGGGAATTAGTCGAATGATTTCTTGTAGCCGCCATCGGTTTTTGGTGCCGGAAGAGC
TCGCCCAAACCCACTCCCATCTCAATATTTCTTGTCGATACTCGTACCCTTACGTGCATC
TCGGATTTCAAATTATTCTCGTACCCATATCCGGCTAGATGCTGGTAATATCCATGGGTG
CAAATACACATCTCTTCCACCTTGCCTAACTCACCCGCTCGCTGATAACCCACAAGTGTA
GNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNCCAATTTATTGATTCGACACAAGTGGA
GCCAAAGAACATTTATAAGCTTTAACAGTTGAGTTGTCAATTCAACCGCACGTGAAAGAC
TT
