| Morex x Barke POPSEQ 2013 | Oregon Wolfe POPSEQ 2013 | Morex Genome Release 2012 |
|---|
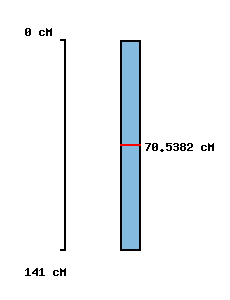 |
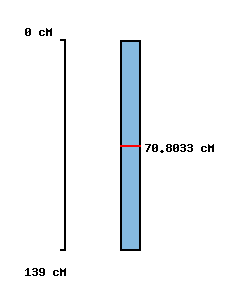 |
No map location |
Predicted Genes from contig_239047
CDS Structure of MLOC_33625

Contig Sequence (1936 bp)
>contig_239047 1936 assembly3_WGSMorex_rbca.fasta
ACAAAATATAGATAAGGAAGTAGCGCCAGCTGACTCTAATGGTAGTGCAGACATGGGGCA
TAATGAGTCTTGTGATCTACTCCCTCTGTACCAAAATAGTTGTAGTTGAGGGAAACTAGT
ACAAGTTTCCCCAACTACAAATACTAGTCGTACACCCGTGCAGCTGCACGGGCTAGCAAC
CTTGGACATATAAATACTATAATTATTAAATACATGTATGTGAAACTTTAGCACTTAGGA
TCCTAGAGAAAAACATCTGCGGGTTAGTGTCATATATTTAATAATGTTGCCCACTTGCCA
TGACATGAATCAACTGCTGAAGCAACAACATGCACTCCCTTGTACTACATCAATGCAATT
GAAGCCTCACAGGTTAATGGAGCAATGAAAAGTATATTAGTAAAACCATGTAGAGTAGCG
ACATATAAAAATGACATGGCAGCAAGGATCGGTGTACACATGCAGGAAGTAGTAGTGAAA
CCTAAATCGAATGCCTCTTTAGATTTTCCATACGTCATAGTTACAATAGCAGTCATCTAT
ATTATTGAAAAAATGCCTAAATTAGGAAGACATAGTGAACAATATCTAATTTTGTTTTCA
ACTACTCAAGCAAATTGGTACTTGTCTGTAACATAAAAGATTCAACACAATTTTCTACAA
TCACCTAGCACATTTATATAATCGCTATGTATATCCCCTCTTCTTAAAGTTTTGTAAAAA
ATAGAAATATTTTTTGAATGACTCTACGGTTTACGGTAAAGAGAAAAGCAACTTTATCAT
ATTAGATAATATTAATGAGTAGAATTTTTTAGAACAACCTGAGCATTGGAGAAGATAAAA
AAAATCAGAACATGTCATGTCTATGGAAGTATGGCCATCATGTGAACCTACAAAACGAAA
AGGAGCATTTAGCTTCTTCCTTATGAAGTATCAAATGTTTATGTGTTATCAAAAGGACTG
GAAATGTTAGCATGCTTTGGAAAATTGTTGTAGATGATTCCATTTGGTGACTGGAAAATT
GTTATAGATGACTGGAAATGTTAGCATGCCATAATTATTTTTCAAGCCCCACATGACTCC
ATTTGGTGACAATTTGTCCATCAGATTTATAATTTGGAAAATTGTTACTTTTTCAGAATA
TTAGTGGACAATACTTCAATCAATTGCATATGGCAAAATTTAATAGCACGGTTGGGGAGT
TTCCTTTTGGAGGTTGATAAACTTACTCACAATAAGGGGAAGGTTGAGTAGTGGATAACC
AAAAATTAACATGTAGCCAAGGAGGATTATTTAGAACTTTGAGAGAAGAGATAATAGAAA
AATGTTTTTCGAGCACCACACAACTTAATTTAGTGAAAAATGTTTTTCGGCTAGTAGGAA
CCAAACTGGGAGAGACTTTTGCTGGTATATGTCAAATCGACTTCCATAATTCTCTTGAAC
TCAGATTACACCGAGGTAATAGAAAACTTACTGGGATGCGACTGTAGAAATTGCGGCTCC
TCTTATACCAAGCTTAAAACCTTATATAAGTAGCGGAAGAAGGACCACAGCAGAAAGATC
CATCTAGGAGAGGCAGCTCCTCAGCCATTCGTCCTCCTCGCCTTCTGTTGGGTTCAACTG
TACCAATTCCGACAACAGAAAAACAAATGTTCCTTCTATCAGAGGAAAACACCAACATAA
TGTCAACTGTTCTTTAGCAGCTAAAAAAAGGATCAGATTTGGTCTGCTCACCTTCACATC
CGTGAGATCGTTCCTCTTCCTGAGATACTTCATGAATTCCCGGAAGTTCACCTCCGTGGG
CCGGTAGTGCCCGCTATGAGGCCAGACAGCCTGAAGACGAAGAAGGGTAACTGAATGAGA
CAGGTGAGCTTGGAACTCCAAACATGAAACTATGACAAGAGTAGAAATCGGCAGATCCAG
GCACCTTTAGGATCCC
