| Morex x Barke POPSEQ 2013 | Oregon Wolfe POPSEQ 2013 | Morex Genome Release 2012 |
|---|
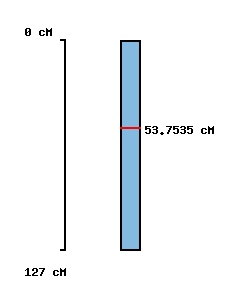 |
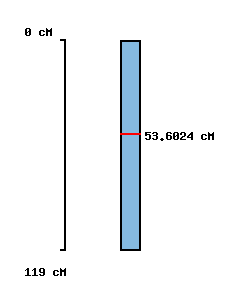 |
No map location |
Predicted Genes from contig_169942
| Gene ID | # CDS Predicted | Max CDS Length | Probes in Cluster | FPKM by Treatment | FPKM by Replicate | Top Rice Hit |
|---|
| MLOC_25561 |
1 |
269 bp |
None |
Available |
Available |
LOC_Os11g26850.3, FRAME:-3, EVALUE:4e-15, 13111.m02571 protein erythronate-4-phosphate dehydrogenase, putative, expressed |
CDS Structure of MLOC_25561

Contig Sequence (1501 bp)
>contig_169942 1501 assembly3_WGSMorex_rbca.fasta
CAAAGAGATGCGATATGTTACAGGCTCGATTGTTATGGCTTAGGATCGGGGTCCCGACAG
GGCACAAAGTCAGAAAGGAACGCCAATGAACCTTGTTTCCAGTCATCATTTTTCGAATAC
GAAGGATGGGGATGGGGATGGACATGGTATCCCGAAGATAATTGAAGAGAAACTAGTAGA
TTTATAAGTAAGTGTAAGTAGCATTACCTGCATCTGTGGCAGAGCACTGACGCACGCTGC
GTGTAAGCTTCAGAATGGTTGGTGTCGAGCTCCAGGAAAGCGTTGAGCAGACCAAGCGCT
CCATCGTATTTCCCGAGGCTCATCATCTCGGAAGCACTCTTAAACAATTTGGAGGGATGA
TTGTCTTGGATTTCTGGAAAGTGTAACTTAGGTAAGGTAGTGTACATAGGAGGATCTAGT
GAGGTGAGGTGGTAAGGTAAAACTAAAAGCGAGAGTAGAGAAAATTCGTGGATGCACGTA
GTCCGTATTACAGGTAGAGAGAGTATGAAACACCCGGTATCGCTACTACGGCTGGTTGAG
TTGCAAATCCTATTTACTTACTCCTACTTACTTACTTACTAGGGATGGGATGGGATGGGA
TGGAATGCAAATGGATTTACAAATTACGATTACCTTGCGAGGAGGAGGAGCATATGAGGA
TTGGGGAATAGAAGAGGAGCAGAGCCTAGCTACTTTACAACGCCCAAATTGCATAGTCGG
GACAAACAGTATCGAATGGTCGAAACGATCGGGCATCAAGCGCGGCCAGTTCCGGCCGAG
ATCCACCCAGATCGACGCGACGGGAAAAGAAATCAGTGGATAATCCCCCTGCGGGGAGAC
GAATGGAGCTCGTACGTGACGGAGAGAGGCGACTCGAATCACCTGGGTGGAGAAGATGTT
GCAGGAGCACCAGCGCGGCGCTGGTCTCGATGAGCAGGGCAGTCTGGATGGTCATGTGGA
GCGAGCCGGAGATTCGGGTGCCCTTGAAGGGCTGCGAGGGGCCGAACTCGGTGCGGCGGG
CCATGAGGCCGGGCATCTCCACTTCGGCCAGCTCGAGCTCGAGGCGGCCGAAGTTGGCCT
GGGAGAGGTCCTTGACCTTGTCTCCCGGCCCGACGAGGTCTTCTCCACGGAGAGCGCCAT
GGAGAAGGTTGGTGGATAGGGTCTGGCGGAGGAGGAAGAAGAATGATTGGAGGGAGGGAG
GAGAGGAGGCGTCGATGGTAGAGGGTGGGGGTCGGCAGCGAGGAGGTGGCCGACGGTGGG
ATAGGGGTCGGGATAGAAGATTGGATTGAGGGGAGACAAGGGAGGGGAAACTTTGGTTGC
ATTGCGGCGGTAGGGGAGAGTGATCCAACTCTGGATCGAGCGAGGAGAGGGGGCTGCTAG
GGTTTGGGTTGGATTGCTGAGACCTGAGAGGTGAATGAGAAACGTTGGATCTTTCGGATG
TGGACAGTTCAGATCGGTTATAGTGGGGTGATCCATGGGAAGAGCCATGATTGGTGGGAT
A
