| Morex x Barke POPSEQ 2013 | Oregon Wolfe POPSEQ 2013 | Morex Genome Release 2012 |
|---|
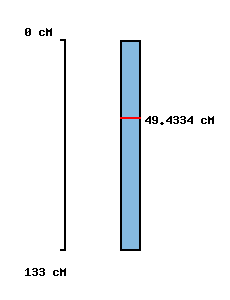 |
No map location | No map location |
Predicted Genes from contig_156934
CDS Structure of MLOC_14887

Contig Sequence (1861 bp)
>contig_156934 1861 assembly3_WGSMorex_rbca.fasta
GGGGGGGGGGGGGGGGGGGTTCCAAAGCTGATACTTTGGGTGTGGAACAGGTTTATCTCA
CATTTTATTGACATTCCTTTTTTCCTTTGAAAAAGATCTGCTGGATCCCACGACCAACTA
TGTTGAAGTATAAGAGAAAGTGCAGCTTTTAAGTAACTTTATTCACTGTAAAGATTAACA
GATGTTGTAGTTGCTAAGTTCTACAGGAATGAAGAACTGCTACGATTTAGCAAGATGATC
AACTAGATTAATTTGCCCTTGACCTCGGTGGCAACTACACTTTGGTATACAATCACAGAA
AGGCAAGCAGACTATCTGTCATATGCTTCCATTCTACAATTTCAGAGACATGATGCATCT
ATACAGCAGTAGTGATTCGAAAGGGTGGGAAGGATCGCCGTGCGTGCCACAGCAGGCTAG
CATTTGCTATCATTTACCAAGATGGTCAACCAGATTAATTTTCCCTTGACCTTAGTGGCA
ACTACACATTGGTATAGATAGATCAGCAGCAACAGCGGAAAGACAAGCAGCTGTTATCTG
TCGTATGCTTGCGATTTGAGAGGCATGATGGACAAAGTAAAAAAAAAACTAGGCGTTAAT
TGTGGGTTTTGCAACCGCCTTAAGTGCAATTATATGCACATTAAGCACAATTATGTGCTA
GGCGTTTTGCTATCTCATAGAGCCTAGCCCATTTTTAACTATATTGATGCATCTATACAG
CAATAGTAATTCAAATGTGTGGGAAGGATCACCGTACGCGCCACAGCAGGCTAGCATTTG
TAAGATCAAAAGGCATAGTTTGGTAGTGCCATCAATTGGAAATACATGGATCTAGAGCAA
TTTAAGTGAAACTTGAGTACGTTGTGGAAAACGGGCTGCAGCTAGCAGACGAAGAGCACT
GTACCTTTTGGTGTGCGTTGTGGCGCTTGCCGGCCCTCCACCTGCGGATCTGGCCGTCCT
TCATCGTTCTGAAGCGGAACTTCATGGACCTGACACACACACAACCATGAGATCCAGAAA
TGCAGGCAATACACTGGCGGTGGAGGGAGGGTGAGTTGGGAACCTACGAGGGTGCCTTCA
TCTTGTATTTCTTGACTTTGGAGATGGTGGGCGTGGTCGGCGCGCGGGACCTGCCCTTGA
TGGCGTAGTGGCGCAGCTGCATCGCCATCACCGGAGGCCGGACGATCGCAGCGGCCGCCG
CCGAGTGGAACAGCGAGCCCATGATGGGCAGAGGCGCGTGGGAGTGGGAGTGGGAGTGGT
CGCGCCGGAAGGGGAGGGAGGGCACGGGCGGGCGGGCATGGACGGCGGTGGGGGCGGAGA
GGAAGCGGCGGGCAAGGCCGCCGGCGGAGGAGCAGCACCACCGCCGCATCGCGCCGTGTT
GTTGCGTGGCGGGCCTCAGCAAGCAGCTAGGGTTTCGATTTGGTTCTCTCCCATCATCCG
AGCGGACTGAGAAGAAACCCAGCCCAGGCTGACGCCTACTACTCCAGCCCAGCCCATTTC
GTACCCCTCGTGTTTATTTTTCCGTAACAACAGGATCGTTTTTTTTTCAATATGAAGAAA
AAAGATCTTTTTTTTGCTAAAAAATTGTGTTTATTATCTGAATAAATCGTATTTATCATT
CATAATATGCTTTCTTGCAAATAAGAGTGTAGATAACACGTATGATTTTCGCTCCCAGCC
AATAGGTCGGGGCTAATTGTGCGTTAATGACCCACAAGTATAGGGGANNNNNNNNNNNNN
NNNCGATAAGTAAGAGCGTCGAATCCAACAAGGAGCACAAGGATCTGACAAATGGTTTCA
GCAAGGTAATCTCTGCAAACACTGAAATTATCGGCAACAAGTAGTTGTGTGATAAGATGA
T
