| Morex x Barke POPSEQ 2013 | Oregon Wolfe POPSEQ 2013 | Morex Genome Release 2012 |
|---|
| No map location | 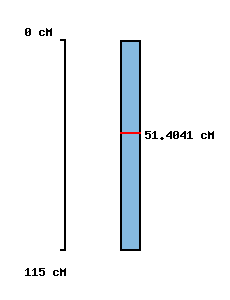 |
No map location |
Predicted Genes from contig_111255
| Gene ID | # CDS Predicted | Max CDS Length | Probes in Cluster | FPKM by Treatment | FPKM by Replicate | Top Rice Hit |
|---|
| MLOC_1289 |
1 |
221 bp |
MLOC_1289.1 |
Available |
Available |
LOC_Os05g48410.1, FRAME:-1, EVALUE:6e-34, 13105.m05148 protein 50S ribosomal protein L21, chloroplast precursor, putative, expressed |
CDS Structure of MLOC_1289

Contig Sequence (2508 bp)
>contig_111255 2508 assembly3_WGSMorex_rbca.fasta
ACCTCTGTCACATCATGAATACAATCAAACATATCCAAACTTGGCACATTTCAATCAAAC
ATGGTTCGCATCAGGTTTACAATCAAAACTAGTTCACATCAGATAACACAACTTAAAAAT
CAAAACAATAACTAGCTCCAATGATCAAGAACTTTGTGCTTCTCCTAACTTCTTCGTTCT
GGACCTTGCGACGTTATCAGACAAAATGGTTAAGAACAAAATAAAAGAAAATCTAACAGC
ACACTAACTTGTAGGCAGTTTGCGTGTGTAAATGAGAGTAAAACAAGCAAAATGAGGCAT
AGAAATCAGTGAATACAAGTAGTAACTGTGAGCAGCGAGTAAATCCTACTCCGATCACAT
CAGGGGTACAATCCTATAAATGCGACATTTTTACCATTTAAGCATAGAAGGACAAGGTAA
ACAACATTTCGATGTTTGAAACAAAGAACTAGAATTTCATGTTTGAACAGCAAAACAATT
GTTTTAGTAGCTCATATGCGGTTTAAATCAGTCCCTAAGGAGAGGCACTTTTACACCAAT
ATTATGCAACATTTGTAGAATTTGAACCTCAAAGAAGTATACATACTTATCATGTTTGCA
CATGGAAGCCAAATACTACACGTGATGTTTAGTACACAAAACATAATTCAGCTAAGTAAT
CAAGAAGGTGGCATAAAAGTAACCATAAATAGCGCATGATTTGTATAAATAACTCATTTG
CTCAACAATTTGATTAGAAAACAGTACCCTAAAGAAGGTAGCAAGCAAACATTTTACTTC
TGAAGATAGGAAACCCATATCATCACCTTCACCACCGCAAGCTTGACTTGGGTATCCATA
CTGAAAAAACAAAGCGCATTTGATTAAGCGAGAAGAAAACAATATAAATCATCTAATGTA
TATTCCATAGCACATGATTCAACATCATGCAAATGCACAGATGCCTATAGACACTGAAAT
AAGAAAACACATACCCACATTCTTATATGTAGTTGTGCTAGGGAATTTTGAAAATGTAAT
AAAATGCAAATAGGAAGAATGTCATGATTGATTTCTATATGAAGATAAACTACAGCCAAA
GGAAGGGTAACAGATGAATAAAAAATCCTGAGATACAAAGGTAAGCTCAGGACACAGAAT
AAAATGAATGGAACTTCAGTACAACCTCCGAATTTTCATATTCACAATATTAAAAGTCAC
CAAGCTGAACATGAGTGTTCAAACTTGACAACTAAGACTAACCAAAAAGCCAAACAGAGC
TAATTCAGGCTACAACAGCAGCACATTAAACTAGCGATGGGCCTACCAAACTCCCAAAGC
ACAACCTACAAGCTAAACTAGAGATTACAGCTGCACCGTGCATTACACAAGTTGGCAAGT
CCAAGTTGATTAGCTACAGGGTAAAACTAATTGTACCAAGTGATTCAAATGACAACAGCA
TCAGAAAAATACCAATTGAATGAGAAGCACAAGCAGACAGAGATCTATGTTTGCTACTGG
AATAATTAAAAGAATTTTATCAACTAGCACTCGTTCACTGCAGTTGTTCCATCATCTTGG
TTTGGAAAATGGTGGGTTTAAGAAAAGTATGATAAGGATGAGGAGTTGTGGCTCGTAACG
CTAATGCAACTAAAATTAGAAGGCCCTAATTATAGATAGTTCTAATCAACCCGTCAACCA
CAACAATTCATGTTCTCAACAAGTCCATAGTCCATACACTTCACCGAGCTTAAAATTCAA
TTCTTGGTACATTATACAGCAACCTCTTAAGCAGCTTCCATGAGGAAAGATGAATATAAA
TGCTATCATACTTGATTGAACAACTAATTTGAACCAATACCTTTAAGTTTCCAGTTCCCA
ACATGCATAGGTCAAAATCAAGCGGAACAAAACGCGATGGGATATCCCGATATACCAATG
GGCACACAACACAAAGACTAATCGTAAATTGCATAAAGTTTTCTTATCAGCTCAGAATTT
GAGGTTTTGGCTGTAATGATATAATCCATCAGCAAATGAACAGAAGATAAGCCAGCACAC
TACAATTTGAGAGGTTGTAATCACATCGGCTACCCTATTAGTCTTAGTCACAGGTTACAA
CTTGAATTGAGGAAACTACATTCAATCGGAATAGTTCTATACGCCCATGTGACACATTAC
CTTGTCATTCACATCGCAGAACTTCAGCCTCTCCGTGAAGATGGAGTCGCCGTTGCTCAC
CTTGAACTGATGCGAACCAATCTATAGGAACAAGCAACAACGCACCGAGGTCACCAACCA
GATCCACTCCCTGGCCCAACCGAAGCCGCCCCGAAGCGCAAAATGGAACAAGATTCGGGC
CTGACCTGGACGACGGTGAATATGGGCTCGTAGGGCTTGAATGGCTTCTCGTCGGTGCCG
AGCGGGCCGACCACCTTGTACCCGATCTCGTCCGCCTCTGCCAGCTTCTCCTCCTCCGTC
TTCCCGTTGGGCGGCTTCCGGCGGGCGTCTCCTCGTCGTCCTCCCCCC
